End-to-End ETL: How to Streamline Data Transfer from Freshdesk to Snowflake with Mage and build Streamlit App
In this article let us see how we can use Mage and perform ETL (extract, transform, load) to transfer data from Freshdesk, a customer support software, to Snowflake, a cloud-based data warehousing platform. The goal of this project is to streamline the process of transferring data from Freshdesk to Snowflake, enabling faster and more efficient data analysis.
The project involves several steps, including creating a Freshdesk API key, setting up a Snowflake account, installing and creating a Mage pipeline, and testing the ETL pipeline flow to ensure that the data is being transferred correctly. The article provides a high level overview of these steps, making it easy for readers to follow along and replicate the process.
We will also see how we can quickly build a Streamlit app using the data in Snowflake and display few basic charts.


Project
We can divide this Project into 3 steps,
- Extract freshdesk data and loading to Snowflake using Python and Mage
- Build the necessary models in Snowflake using DBT
- Build custom application using Streamlit
The github link of the project can be found here
Step 1: Extract and Load

Note: The assumption in this article is that the reader has the basic understanding of Mage tool and this article doesn’t cover how to create Mage project and add different task blocks.
High level entity relationship diagram for the Freshdesk data is as shown below. It is highly recommended to have a ER diagram before starting any ETL or Data related projects as ER diagrams are a valuable step in the architecture design phase and helps in communication, maintenance, and documentation. It ensures that the ETL is well-designed, well-understood, and well-maintained.

The Mage data workflow has 3 task blocks,
load_freshdesk_data
This is a dataloader block that uses freshdesk APIs to extract the data.
Freshdesk provides a set of RESTful APIs that allow developers to access data stored in their platform. These APIs can be used to extract data such as tickets, contacts, companies, and more. The python requests module is a popular library that allows developers to make HTTP requests, including API requests.
Freshdesk API documentation can be found here https://developers.freshdesk.com/api
In this project we are extracting the following data using Freshdesk APIs,
- tickets
- agents
- companies
- contacts
- groups
To extract data from Freshdesk using the request module, you’ll first need to authenticate your API requests. Freshdesk uses API keys for authentication, which can be generated in the Freshdesk portal under the “Profile Settings” section. Once you have an API key, you can use it to authenticate your requests.
To make a request to the Freshdesk API using the request module, you’ll need to specify the API endpoint, along with any necessary parameters or headers. For example, to retrieve a list of all tickets in Freshdesk, you can make a GET request to the /api/v2/tickets endpoint. Here's an example of how to do this using the requests module in Python:
import requests
from requests.auth import HTTPBasicAuth
domain = 'yourdomain'
api_key = 'your_api_key'
url = f'https://{domain}.freshdesk.com/api/v2/tickets'
auth = HTTPBasicAuth(api_key, 'x')
response = requests.get(url, auth=auth)
if response.status_code == 200:
tickets = response.json()
print(tickets)In this example, we’re using the requests.get() method to make a GET request to the /api/v2/tickets endpoint. We're also specifying the authdetails using our API key. If the request is successful (i.e. we receive a 200 status code), we parse the JSON response into a Python object and print it to the console.
Using the Requests module in this way, you can extract data from Freshdesk and use it for further processing or analysis in Python. You can also use other HTTP methods, such as POST, PUT, and DELETE, to perform other operations on Freshdesk entities.
transform_data
This block gets the data from the above step and does some basic data cleansing, enrichment tasks and selects the columns that are of interest.
The transformed data is then pushed to the next task block which exports the data to Snowflake.
export_snowflake
This task block connects to Snowflake, establishes the session and exports the transformed data to Snowflake. By the end of this step the relevant tables get created in Snowflake.
The following code snippet handles the export of pandas dataframe to Snowflake table in Mage
with Snowflake.with_config(ConfigFileLoader(config_path, config_profile)) as loader:
loader.export(
DataFrame(value),
key.upper(),
database,
schema,
if_exists='replace', # Specify resolution policy if table already exists
)Step 2: Build Data Models
In this step we can use DBT block in Mage or separate DBT installation to connect to Snowflake and build some data models that are needed for analysis and visualisation.
Note: Again this article does not cover the basics & installation of DBT but just talks about how DBT is used in the project
Below is one such data model which calculates the number of Freshdesk tickets raised per company,
with tickets as (
select * from {{ source("fd_source","tickets") }}
),
companies as (
select "company_id", "name" as "company_name" from {{ source("fd_source","companies") }}
),
agg_tickets as (
select "company_id", count(*) as "ticket_count" from tickets group by "company_id"
),
final as (
select "company_name","ticket_count" from agg_tickets t
inner join companies c
on t."company_id" = c."company_id"
)
select * from finalOnce we have all the necessary SQLs (like the one above) ready, we can then trigger dbt run command to materialise all the models in Snowflake.
This can be accomplished using the DBT model node in Mage too.
Step 3: Build apps using Streamlit
In this step we read the data from Snowflake tables and build few charts using Streamlit. We need the following python libraries to be installed before building the streamlit application,
pip install streamlit
pip install plotly
pip install "snowflake-snowpark-python[pandas]"Streamlit is a popular open-source framework for building data science web applications in Python. It allows developers to easily create interactive apps that can be shared and deployed with just a few lines of code.
In this project, we’re establishing a connection to Snowflake using the snowflake.snowpark library and retrieving data from a Snowflake tables. We then convert the results to a Pandas DataFrame, which is a common data structure used in data science applications.
Once the table data is retrieved from Snowflake and converted to a Pandas DataFrame, we can use Streamlit to build an app that displays and interacts with the data. Here’s an example of how to build a simple Streamlit app that displays the data in a table:
import streamlit as st
from snowflake.snowpark import Session
import plotly.express as px
st.title('❄️ Streamlit - Snowflake ❄️ ')
session = Session.builder.configs(st.secrets.snowflake).create()
table = session.table(table_name)
table = table.limit(10)
table = table.collect()
st.dataframe(df)
# Use plotly to plot a bar graph
fig1 = px.bar(df, x='ticket_resolution_in_hours', y='total_tickets', color='total_tickets')
st.plotly_chart(fig1, use_container_width=True)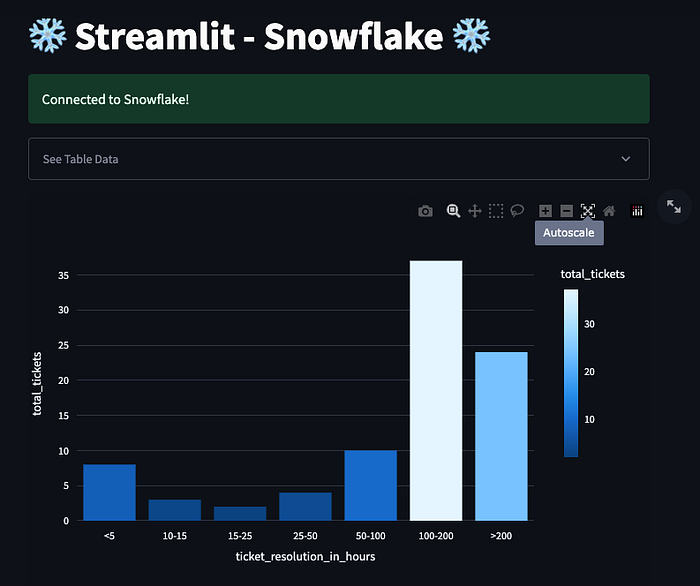
Using Streamlit in this way, we can quickly and easily build interactive data science web applications that read data from Snowflake. We can also add other Streamlit components such as sliders, drop-downs, and plots to create more complex and interactive apps.
Refer: https://towardsdatascience.com/how-to-connect-streamlit-to-snowflake-b93256d80a40 for more details on how to use streamlit.
In summary, in this article we saw how we can build an end to end ETL data engineering project using modern data engineering tools and how quickly we can build interactive web applications using Streamlit.
Thanks for reading and reach out for any questions and suggestions.
